



If you want to automatically post content from one site to another, then WordPress and RSS feeds are a match made in heaven.
Content aggregation and curation from other sites can help turn your site into a hub for the latest blog posts, eCommerce news, local jobs, videos, fan page content – you name it, there’ll be a niche that your content aggregation site can fill.
What’s more, bringing in quality traffic will generate lots of new backlinks, enhance your online presence, gain audience trust and ultimately boost your SEO! Truly a content marketer’s dream.
You’ll need a WordPress plugin that automatically creates posts from an RSS or Atom feed, and that’s exactly what the WP RSS Aggregator plugin will do for you.

What You’ll Need
To start autoposting from one site to another, you’ll need:
- The source site and its RSS/Atom feed
- A WordPress website
- WP RSS Aggregator Pro
The site from which you will retrieve the content (the source site) can be:
- a WordPress site,
- a non-WordPress site,
- or any other web-enabled app that can provide an RSS feed.
The RSS/Atom feed will be used as the feed source for your imported content.
WP RSS Aggregator will import the content from the source site using the RSS feed you insert.
The Pro Plan will then allow you to import those RSS Feeds into posts or any custom post type within minutes. It includes options such as automatically assigning a post type, the post status, categories, tags, images, authors, and more.
To get started, simply install and activate the plugins and follow the instructions below to have your content streamed automatically into your site.

AutoPost from one site to another with WordPress and the WP RSS Aggregator plugin.
Get WP RSS AggregatorImporting content from one site to another
Add a Feed Source and Import Content
The first thing we need to do is to add a new feed source in WP RSS Aggregator. Head over to RSS Aggregator > Add New in your WordPress dashboard (/wp-admin).
From here, enter the feed URL of the site you want to extract feeds from. You can also set a limit on the number of items to be stored so as not to bombard your database over time.
Not sure how to find an RSS feed for your source site? Follow this guide.
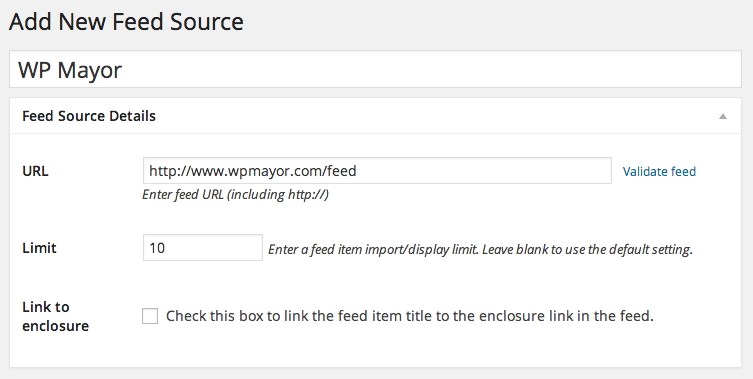
There are many more options you can set. But I will skip those as they are pretty intuitive and nicely covered in the knowledge base.
Most of them will depend on your personal preferences. For instance, you can import posts as Drafts to review before publishing or just publish them automatically.
Once we have the feed source set up, you can continue adding more sources at will – there is no limit.
The Add-ons
You have all the flexibility you could want when importing content with the WP RSS Aggregator Pro Plan.
It’s a discounted bundle of all the powerful add-ons, including:
- the Feed to Post add-on,
- the Full-Text RSS Feeds add-on,
- the Keyword Filtering add-on,
- and more features that offer greatly improved functionality over the free version.
Check out the Pro pricing over on the WP RSS Aggregator site.

Full Text connects Feed to Post to WP RSS Aggregator’s premium full-text service. This will bring in the full content for source sites. This is especially helpful if the RSS feed is limited to a short snippet of the original content. Or, if it does not include images.
Keyword Filtering adds to it by enabling you to filter out any unwanted posts or filter through only the ones that meet your requirements. For example, only import posts that contain a specific keyword or are part of a particular category.
Importing Social Media Content
WP RSS Aggregator supports the importing of content from a wide range of social networks to be displayed on your site as WordPress posts.
This can be really helpful if you do the majority of your important content creation on your various social media accounts – videos on YouTube, images on Instagram, stories on your Facebook page, and so on – and you want to aggregate it all on one WordPress blog to create a complete portfolio of your social media posts.
You can import content from any social media network which supports RSS feeds (e.g. Flickr or Tumblr), or for which you can create your own custom RSS feed (e.g. LinkedIn or some of the social media sites below).
It’s easy to configure WP RSS Aggregator’s Feed-to-Post add-on for the most commonly used social media platforms:
- Facebook – although Facebook no longer provides RSS feeds by default, we use third-party services to generate RSS feeds for Facebook accounts. The Feed to Post add-on can then import text and incorporate featured images on Facebook directly into the WordPress post content.
- Twitter – Twitter also no longer provides RSS feeds by default but by using third-party services, Feed-to-Post can grab new content on your Twitter feed and add it to your WordPress site.
- YouTube – by enabling the “allow embedded content” option in Feed-to-Post’s settings, YouTube videos can be automatically imported and displayed in new WordPress posts.
- Reddit – Reddit offers a number of RSS features by default, and by grabbing the feed source and setting it up on WP RSS Aggregator on your WordPress website, you can auto publish new posts on a given subreddit directly to your blog
- Instagram – Instagram doesn’t support RSS feeds by default, but we can use third-party services to generate RSS feeds for Instagram posts. You can then simply set up an automation to grab pictures and captions (#so #many #hashtags) from an Instagram feed and generate new WordPress posts.
Displaying Your Posts
Once the feed sources are set up and the posts are being imported, you need to display them. This is left entirely up to your theme or page builder. Feed-to-Post can also integrate with Google’s URL Shortener API to create short, easy-to-remember URLs for your published posts.
That’s the beauty of WP RSS Aggregator.
It lets you display the content anywhere you want without getting in the way.
By default, the posts will show up on your website’s blog along with all your old posts, but you can also import them as custom post types to feature them elsewhere. You can also display imported posts using the shortcode or Gutenberg block anywhere on your site.
You can build custom views with plugins such as Toolset. It’s a great solution if you’re not a developer and don’t want to mess around with any HTML yourself.
If you prefer page builders, plugins such as Elementor, Beaver Builder, and Divi all offer sleek displays for posts that can be style just the way you want them.
The WP RSS Aggregator website has a detailed knowledgebase and tutorials to help you explore a wide range of additional use cases and get the most out of the best WordPress aggregation plugin around.
AutoPost from one site to another with WordPress and WP RSS Aggregator Pro.
Get WP RSS AggregatorSummary
There you have it! You’ve just created your very own content aggregator site!
To recap, to start autoposting from one site to another, you’ll need:
- The source site and its RSS/Atom feed
- A WordPress website
- WP RSS Aggregator Pro

40 Responses
Hi, how would you do it without RSS but with WordPress Rest API : is there a plugin for that ? connect to the API of another wordpress with authentication to retrieve specific posts and insert them in a post grid for example ?
Hi plancton, not that I’m aware of at the moment. Is there a particular reason you’d like to use the REST API over RSS in your case?
Thanks for sharing the helpful post with us. Appreciated.
It is really helpful.. Thanks
You’re welcome, Jikola.
I love this tutorial and I will try the ways listed here. thanks for the post.
I have an RSS feed subscription site that requires that I log in first before I can get the content to post on my site. how do i use the plugin to get the content from the site where I have to login first
I’ve been searching for in a while now. Thanks very much.
You’re welcome!
You’re welcome!
Hi, is this the same for outoposts from website to an app (our own app) will this work to publish from the site blog to the apps’ feed?
Hi Rita, we have an article about doing something like that here:
https://wpmayor.com/create-mobile-app-news-curation-website/
You’re welcome, Michael.
You’re welcome!
Thanks for this great info, and please hope it won’t cause google penalty?
Hey Daniel, this video should help you out to understand it:
Thanks
You’re welcome!
WP RSS does not work as described in the article. After purchasing the premium plugin to do exact this (post from site A to B) we have found WP RSS does not retain the same format, in fact we have found several flaw such as not retaining the featured image from the original post from Site A). For several months I have written WP RSS regarding this exact issue only to be met with “we only handle the importing, not the exporting”. I have been a long time user of this plugin until wanting to do exacting what the article states “how to auto post from one site to another”. .no more.
Hi John, sorry to hear about this.
Are you referring to the WordPress Post Format here? What happens exactly?
As for the featured image, this would depend on whether the RSS feed provides it or not, unless you opt for the Full Text add-on. Even if so, some sites have strange page structures with the featured image outside the content area, which our plugin cannot reach.
I’m not sure what you’re referring to when you mention “not the exporting”. Do you mean the display of the imported content?
I’ll look into the support requests you sent us to see what went wrong. Please reply to them and ask for me directly, referring to this comment.
This is amazing i have to try this.
Hey Wayne, that’s great! Have you given it a go?
very helpful thank you
You’re welcome, George.
Thanks for publishing this helpful post
You’re welcome, Belly.
It works!! yaay!!
That’s great! Feel free to share your use of the plugin 🙂
does the post created from RSSAggregator and Feed to post from Site A to Site B contain all the formats as available in the original post in Site B
Won’t Google see this as duplicate content and penalize you for that manner..?
Hi Johan, we had missed your question, I’m sorry.
This FAQ should help answer this question:
Hello,
Thanks a lot for this informative article. I have a question though. after i import the RSS feed from website A to website B, using feed to post. now if I am sharing a post from website B in a social media, when the users click on that link, where will he be navigated to? website A or website B. I need the user to get navigated to website A(i.e the source website of the RSS feed)
Is this possible??
By default he will be sent to Website B since the post is on that site. However, you can use the filter I linked below to change the post’s behaviour, which should then be reflected in the social sharing plugin.
Filter: https://kb.wprssaggregator.com/article/295-f2p-filter-make-post-titles-link-directly-to-the-original-article
Wow this is all I’ve been searching for in a while now. Thanks very much. leaving a comment from WebprofTech
Super idea for me
I installed the plugin, but when I got to the Feed to Post add-on, I realized it cost $60 for a single site. That would have been nice to know before I installed this. Time to uninstall.
Hey Phids, yes, Feed to Post is a premium add-on. This is an old post so I’ll head in and update some details and add the price to make that more clear.
Nevertheless, we strongly believe our add-ons are great value for money. If you’d like to know more about them or have any questions about your use-case, please contact us on the link below. We’ll be more than happy to help.
https://www.wprssaggregator.com/contact/
its really helpful psot for bloggers 🙂
Thank you indeed, useful.
Thanks..helpfull your post.